
Research Overview
My research develops theoretically grounded and scalable algorithms for machine learning and Bayesian inference. I focus on active learning, optimal experimental design, and efficient MCMC methods for large-scale inverse problems. My work integrates optimization, non-asymptotic statistical analysis, and numerical linear algebra with high-performance computing to design algorithms that are both provably efficient and practically scalable.
1. Efficient MCMC for Bayesian Inverse Problems with Approximate Operators
Publications: AISTATS 2026 · ICML 2026 submission
Overview
Many Bayesian inverse problems require repeated evaluations of expensive forward operators (e.g., PDE solvers). While approximate operators are often available (coarse discretizations, truncated solvers, or learned surrogates), naïvely using them in MCMC leads to bias amplification and poor mixing.
We develop independence Metropolis–Hastings (IMH) samplers that exploit approximate posterior models while preserving the exact target distribution and improving mixing behavior. In particular, Latent-IMH constructs proposals in a latent variable space, while Proximal-IMH applies a proximal correction that rebalances likelihood and prior curvature using the exact forward operator.
Theoretical Contributions
We provide non-asymptotic analysis for linear forward models with Gaussian noise under structured prior assumptions:
KL divergence bounds (Gaussian prior):
Under a Gaussian prior, we derive explicit upper bounds on the expected Kullback–Leibler divergence between the proposal distribution and the exact posterior.Mixing-time bounds (log-concave prior):
Under log-concave priors, we establish non-asymptotic mixing-time bounds for Approx-IMH, Latent-IMH, and Proximal-IMH.Improved conditioning dependence:
The analysis shows that Approx-IMH amplifies signal-to-noise effects, whereas Proximal-IMH eliminates this amplification and achieves strictly improved dependence on the conditioning of the forward operator.
Empirical Results
Across linear, multimodal, and nonlinear inverse problems, Proximal-IMH achieves:
- Higher acceptance rates
- Faster decay of relative mean error
- Improved effective sample size per forward solve
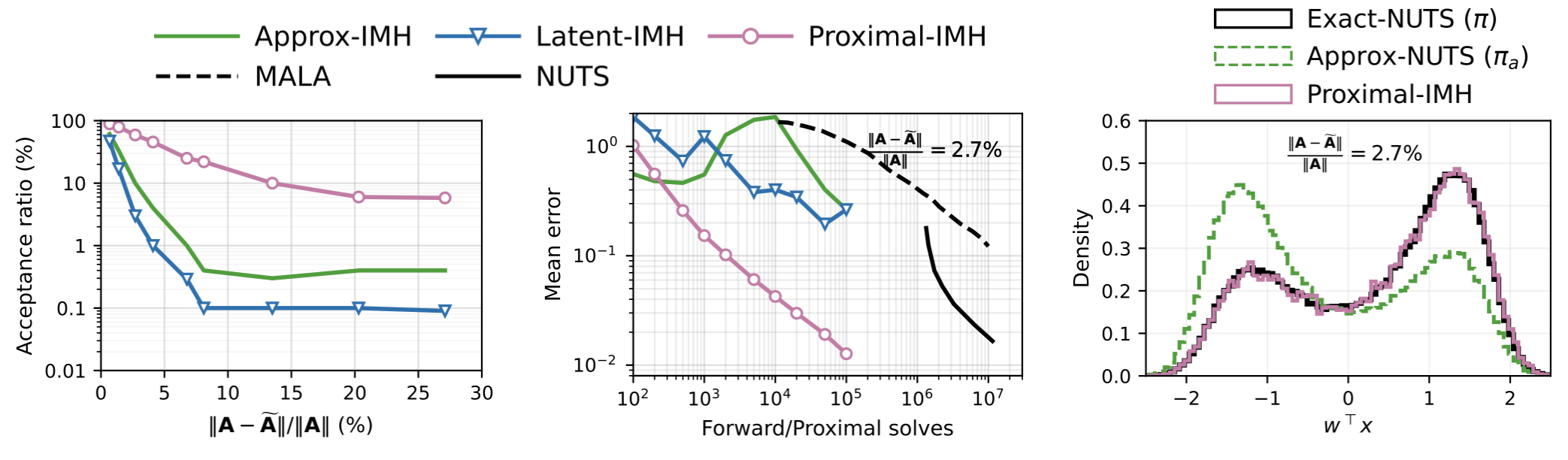
Left: Acceptance ratio versus operator error \(\|\mathbf{A}-\tilde{\mathbf{A}}\|/\|\mathbf{A}\|\). Proximal-IMH remains stable as approximation error increases, while Approx-IMH and Latent-IMH deteriorate. Middle: Mean error versus forward/proximal solves. Proximal-IMH achieves faster error decay compared to Approx-IMH and gradient-based baselines. Right: Projection density along $w^\top x$ under a double-well prior. Proximal-IMH closely matches the exact posterior, while Approx-NUTS exhibits visible bias.
2. FIRAL & Approx-FIRAL: Active Learning with Statistical Guarantees
Publications: NeurIPS 2023 · SC 2024 (Best Student Paper Finalist)
Overview
We study pool-based batch active learning probelm for multiclass classification using multinomial logistic regression. Our goal is to select a small subset of points for labeling that provably minimizes the generalization error on the unlabeled pool.
We show that the Fisher Information Ratio (FIR) tightly characterizes excess risk and use this insight to design algorithms with statistical guarantees and scalable implementations.
FIRAL (NeurIPS 2023): Theory and Near-Optimal Selection
We prove that, under sub-Gaussian assumptions, the excess risk admits a non-asymptotic characterization
\[R_p(\theta_n) \asymp \frac{1}{n}\,\mathrm{Trace}(H_q^{-1}H_p),\]establishing the Fisher Information Ratio (FIR) as both a non-asymptotic upper and lower bound on excess risk.
We then formulate batch active learning as minimizing FIR:
\[\min_{z \in \{0,1\}^m,\ \|z\|_1=b}\ \mathrm{Trace}\big((H_0 + H_z)^{-1} H_p\big).\]an NP-hard combinatorial problem.
Our FIRAL algorithm:
- Solves a convex relaxation via mirror descent
- Rounds the solution using regret minimization
- Achieves a (1+ε)-approximation guarantee
- Requires only \(O(cd / \varepsilon^2)\) labeled samples
Empirically, FIRAL consistently outperforms uncertainty sampling, entropy-based methods, and diversity-based baselines on MNIST, CIFAR-10, and ImageNet.
Approx-FIRAL (SC 2024): Scalable Active Learning
While FIRAL has strong statistical guarantees, it involves dense Hessian operations with cubic dependence on the number of classes.
To address the scalability challenge, we developed Approx-FIRAL, which:
- Exploits Kronecker structure of the multinomial logistic Hessian
- Uses matrix-free Hessian–vector products
- Applies randomized trace estimation
- Incorporates preconditioned conjugate gradients
- Reduces storage from $O(c^2)$ to $O(c)$ and computational complexity from $O(c^3)$ to $O(c)$ in the number of classes $c$.
We implemented a distributed multi-GPU version using MPI and CUDA-enabled Python.
Approx-FIRAL:
- Matches the statistical accuracy of FIRAL
- Scales to ImageNet (1.3M points, 1000 classes)
- Demonstrates strong and weak scaling on up to 12 GPUs
- Was selected as a Best Student Paper Finalist at SC 2024
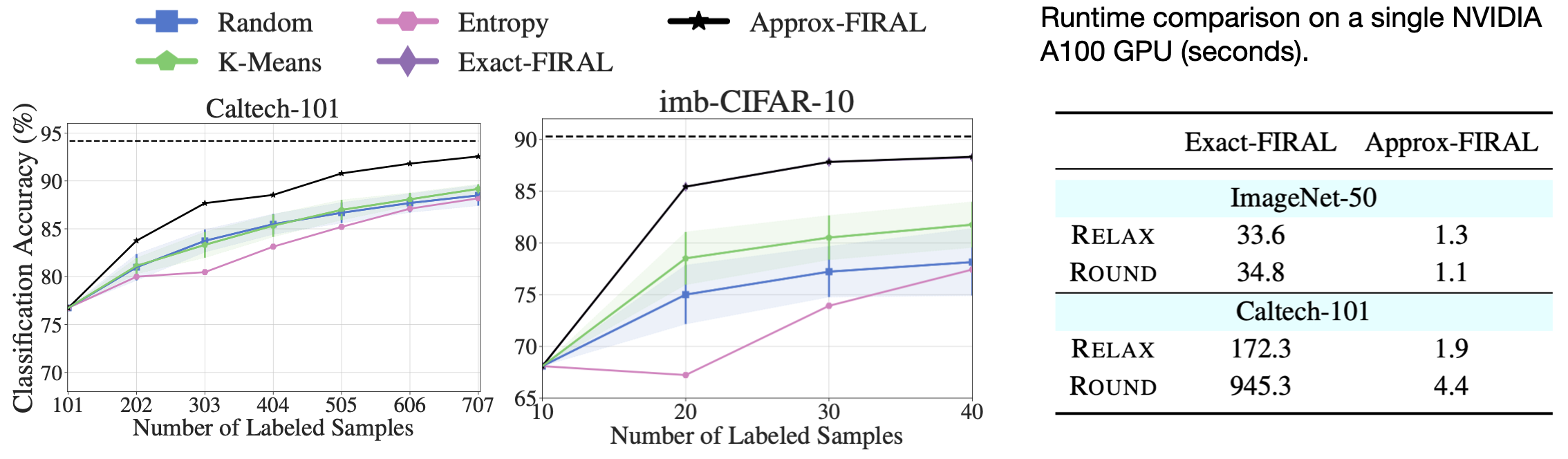
Left and middle: Approx-FIRAL preserves the predictive accuracy of FIRAL. Right: substantial single-GPU speedup.
Broader Impact
This work bridges:
- Statistical learning theory
- Combinatorial optimization
- Online regret minimization
- Randomized numerical linear algebra
- High-performance computing
It provides one of the few active learning algorithms with both non-asymptotic statistical guarantees and large-scale GPU implementations.
3. Optimal Experimental Design via Regret Minimization
Publication: SIAM Journal on Matrix Analysis and Applications (SIMAX) (accepted, 2026)
Paper
Overview
We study one-shot, label-free subset selection from a large unlabeled pool for multiclass classification. Using finite-sample learning theory, we connect excess risk in multinomial logistic regression to the Fisher Information Ratio (FIR) and show that it admits a V-optimal design relaxation that depends only on unlabeled features.
Building on the Regret-Min framework, we develop entropy-regularized rounding algorithms with provable $(1+\varepsilon)$-approximation guarantees and near-optimal sample complexity. We further extend the analysis to ridge-regularized experimental design while preserving comparable theoretical guarantees.
Theoretical Contributions
Excess Risk and Design Connection:
We prove that the excess risk of multiclass logistic regression can be bounded in terms of the V-optimal design objective, providing a principled statistical justification for label-free subset selection.Entropy-Regularized Regret-Min:
We incorporate entropy regularization into the Regret-Min framework and establish a $(1+\varepsilon)$-approximation guarantee with sample complexity $\tilde{O}(d/\varepsilon^2)$, matching guarantees previously known for $\ell_{1/2}$ regularization.Sharper Sample-Dependent Bounds:
Under favorable conditions, we derive improved bounds of order $\tilde{O}(d/\varepsilon)$.Extension to Ridge-Regularized Design:
We extend the regret-minimization analysis to ridge-regularized optimal design and prove that near-optimal guarantees are preserved despite the additional regularization term.
Empirical Results
We validate the theoretical predictions on MNIST, CIFAR-10, and ImageNet-50.
- Regret-Min consistently improves downstream classification accuracy compared to common baselines.
- The entropy regularizer exhibits more stable alignment between the design objective and generalization error.
- Numerical experiments confirm the predicted relationship between eigenvalue growth and near-optimality guarantees.
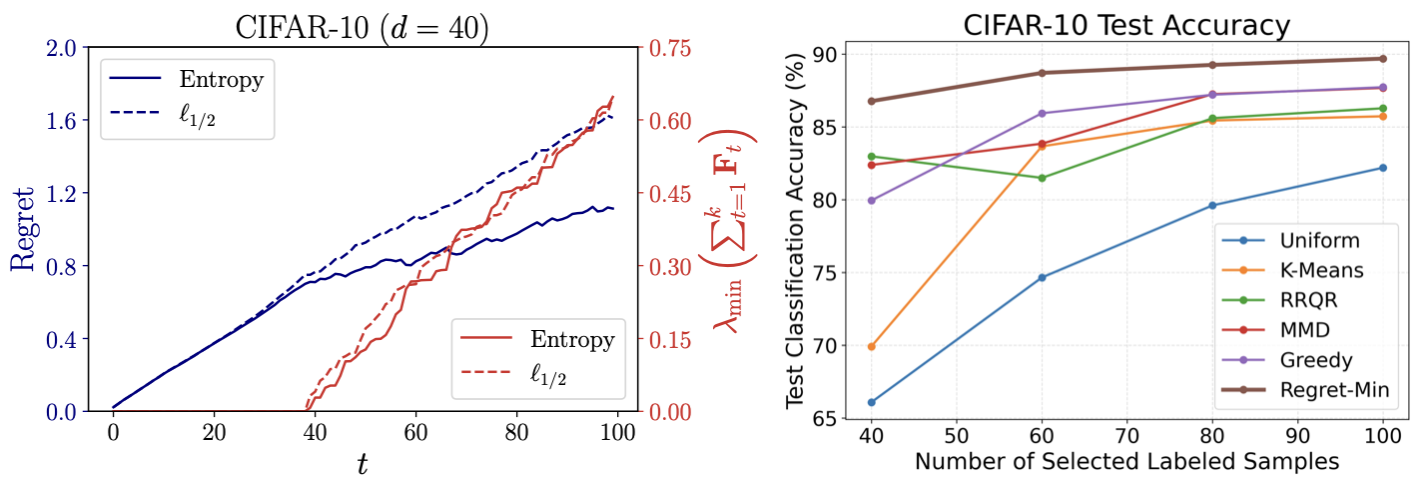
CIFAR-10 (SimCLR embeddings projected to 40 dimensions via PCA). Left: Rounding dynamics during subset selection—although regret trajectories differ between entropy and \(\ell_{1/2}\) regularization, both achieve comparable growth of the minimum eigenvalue that governs near-optimality. Right: Regret-Min consistently yields higher downstream classification accuracy than classical sampling baselines as the labeling budget increases.
4. kNN-DBSCAN: Scalable Density-Based Clustering in High Dimensions
Publication: ACM Transactions on Parallel Computing (TOPC), 2025
Paper
Overview
DBSCAN is a widely used density-based clustering algorithm, but it faces two fundamental limitations in large-scale and high-dimensional settings. First, it depends on constructing the $\varepsilon$-neighborhood graph ($\varepsilon$-NNG); in high dimensions, range-search queries become computationally expensive, and the storage complexity is unpredictable since the number of neighbors within each $\varepsilon$-ball varies across points. Second, parameter tuning is inefficient: selecting $(\varepsilon, \text{minPts})$ often requires multiple runs, and any change forces reconstruction of the $\varepsilon$-NNG from scratch.
We develop kNN-DBSCAN, which replaces the $\varepsilon$-NNG with a $k$-nearest-neighbor ($k$NN) graph. Once constructed, the $k$NN graph can be reused across parameter choices, improving scalability while preserving the density-based clustering semantics of DBSCAN.
Theoretical Contributions
New Clustering Definition: We introduce kNN-DBSCAN by redefining reachability using the $k$-nearest-neighbor graph while preserving the core/border/noise classification of DBSCAN.
Formal Relationship with DBSCAN: We establish precise relationships between DBSCAN and kNN-DBSCAN. In particular, every kNN-DBSCAN cluster is contained within a DBSCAN cluster on core points, and the two methods coincide when their cluster counts agree.
MST Reformulation: We show that clustering core points in both DBSCAN and kNN-DBSCAN is equivalent to computing connected components of a minimum spanning tree (MST) of the corresponding neighborhood graph.
Correctness of Inexact Distributed MST: We introduce an inexact distributed MST construction and prove that it preserves clustering results despite graph partitioning and communication constraints.
Parallel Algorithm and Scalability
We develop a hybrid MPI/OpenMP implementation that:
- Uses randomized kNN graph construction
- Applies parallel Borůvka-style MST algorithms
- Minimizes communication via partition-aware inexact MST construction
Our implementation achieves:
- 1 billion 3D points clustered in under 1 second (28K cores)
- 65 billion points in 20 dimensions clustered in under 40 seconds (114,688 cores)
- Up to 37× speedup over prior parallel DBSCAN methods
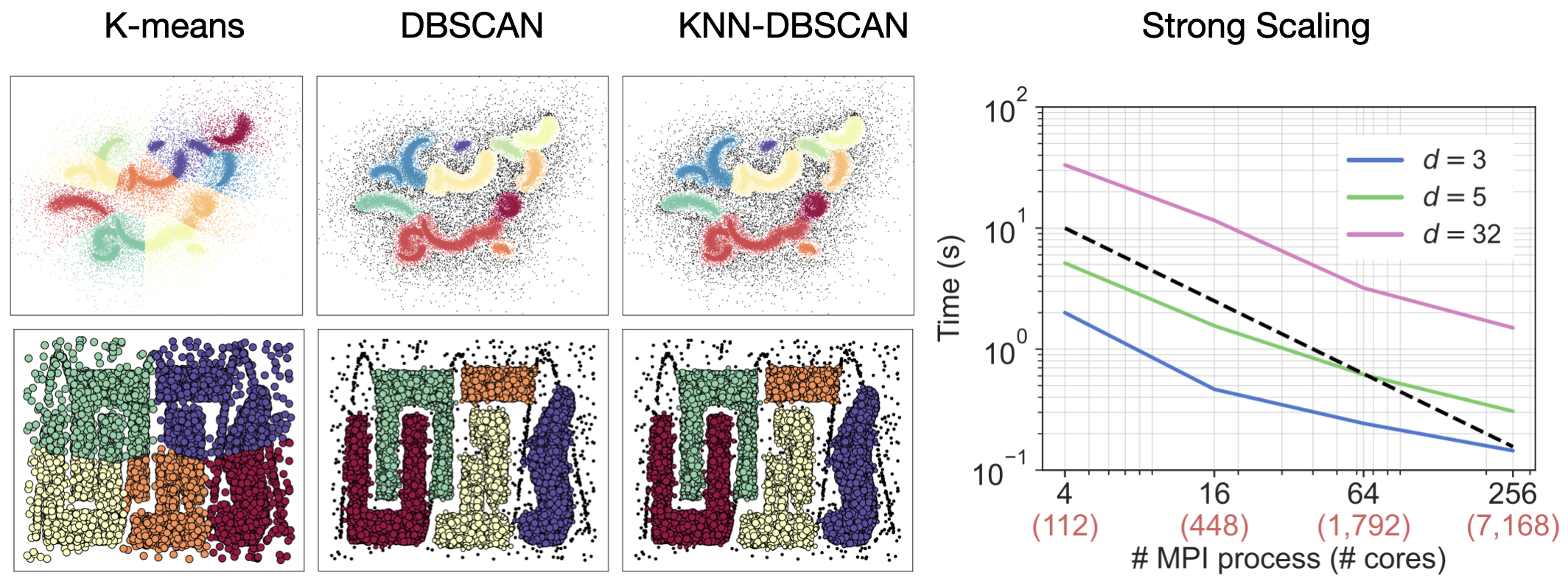
Left: K-means fails on nonlinearly separable data, while DBSCAN and kNN-DBSCAN recover the density-based clusters. kNN-DBSCAN preserves DBSCAN’s clustering structure. Right: Strong scaling across dimensions.